Vision: "Make AI easy to use, understand, access, and operationalize."
Self-improving agent-driven execution intelligence for model deployment and inference
Deploy models from Hugging Face, S3, or GCS without managing clusters, runtimes, or cloud infrastructure.

$ nexplane run --workload inference --model llama-3.1-8b Plan generated: accelerator: 1× L4 estimated cost: $24.80 time to ready: ~12m serving mode: continuous Proceed? y Status: running [infer] endpoint live https://run.nexplane.dev/… [infer] health check ok [infer] p50 latency 42ms
Model deployment and inference on one platform
Deploy, serve, and monitor models — without managing clusters.
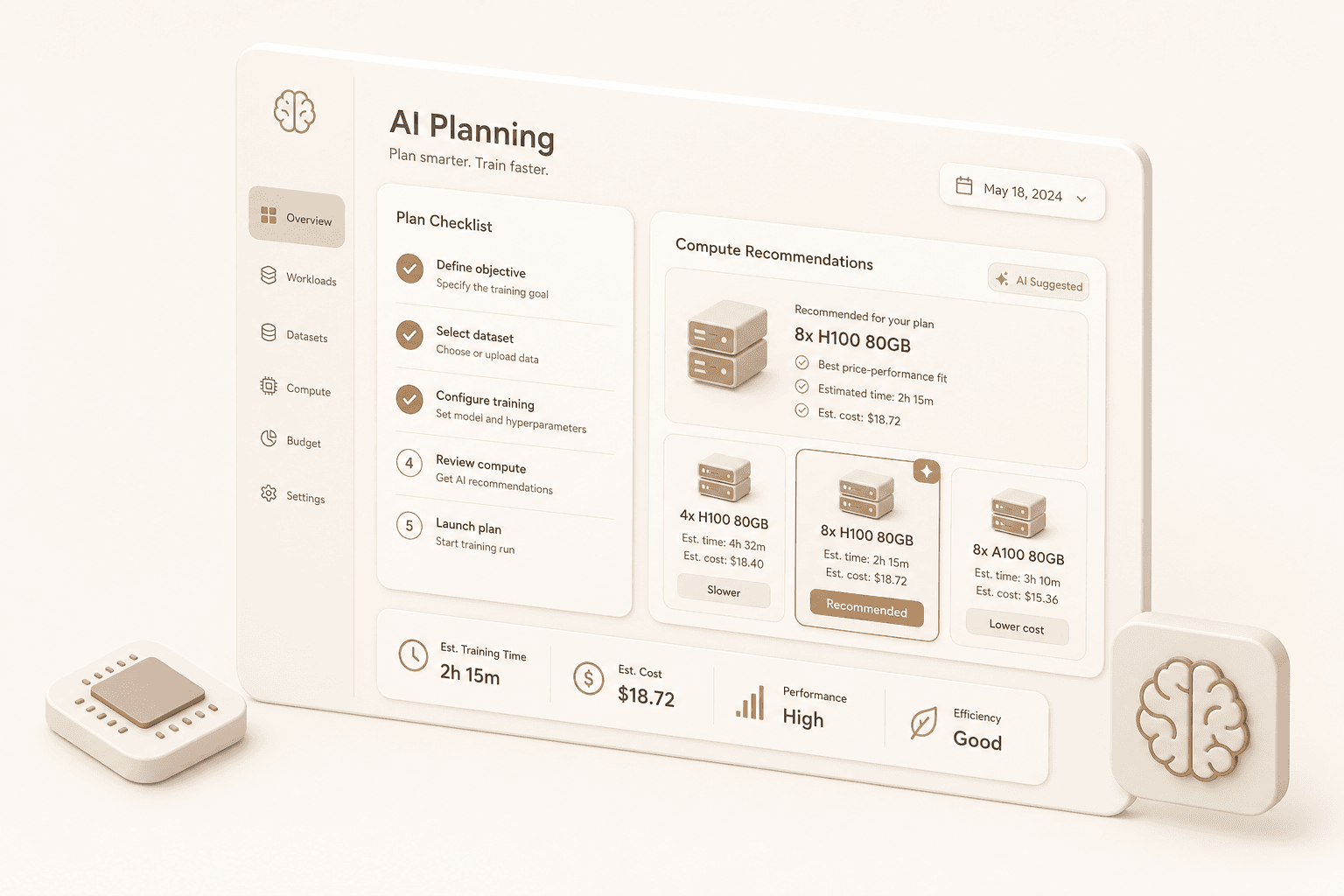
Agent-planned deployments
Nexplane inspects each inference deployment and recommends serving stack, capacity, time-to-ready, cost, and reliability settings.
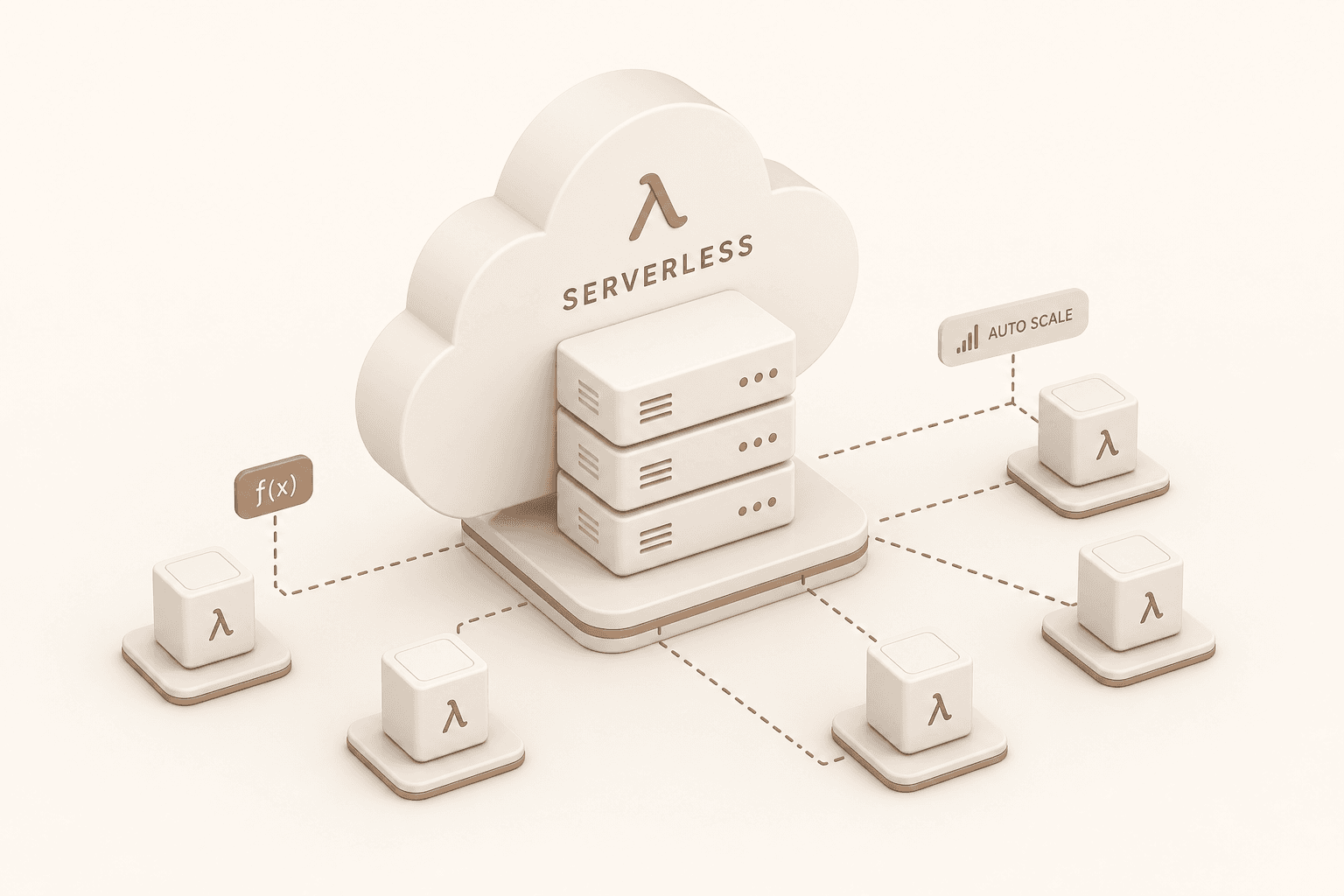
Serverless execution
Connect a model, set a deadline, and deploy. Nexplane handles capacity planning, cost estimates, endpoints, orchestration, logs, and monitoring.

Failure-aware recovery
Detect failures, retry intelligently, and keep inference endpoints healthy.

Deployment control
Set latency targets, replica bounds, and serving preferences while agents handle infrastructure.
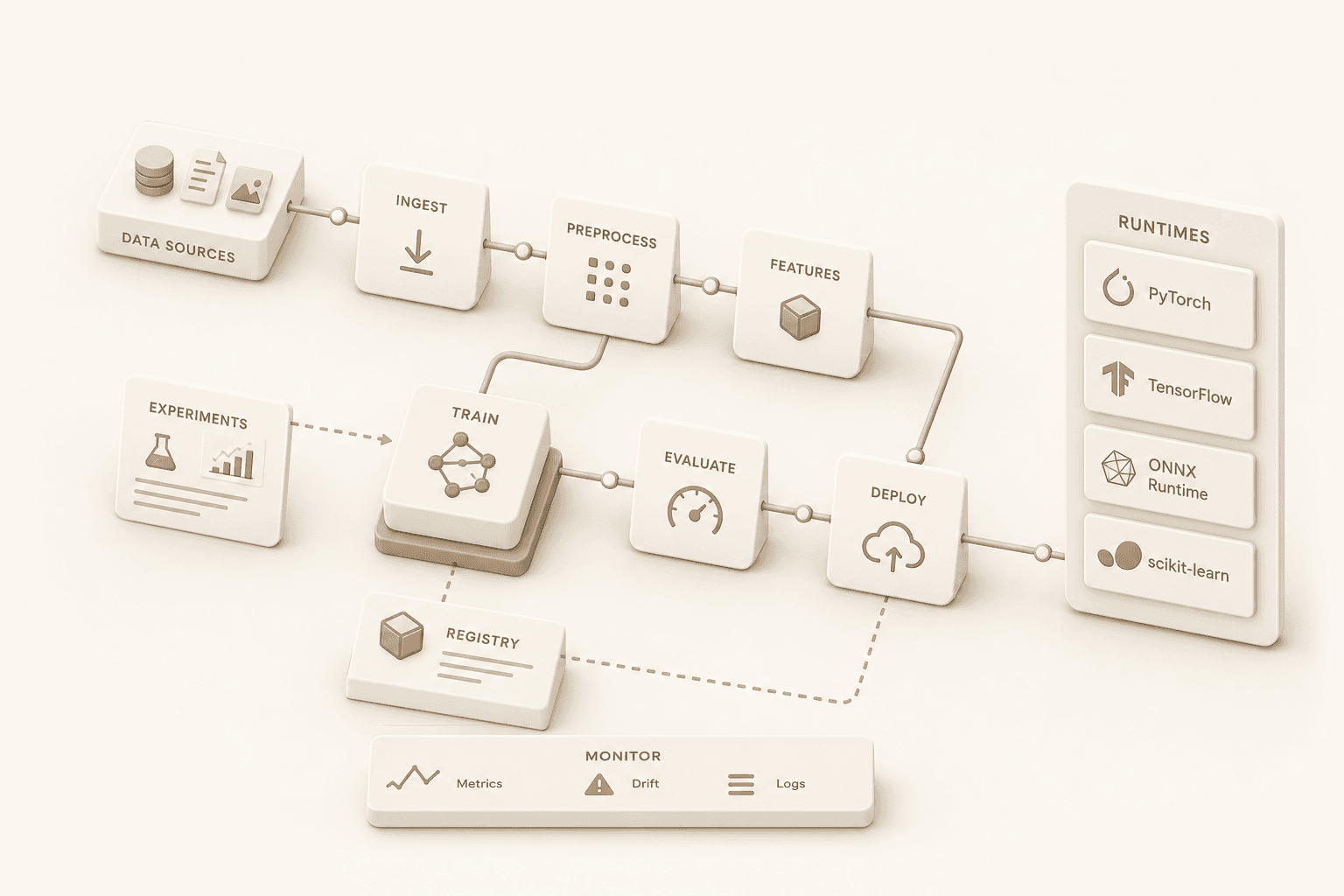
Runtime agnostic
vLLM, TGI, Ray Serve, and custom stacks — across clouds and accelerators.
Three modes. One platform.
Simple defaults for most users. Full control for advanced users.

- →Model source, deployment name, deadline
- →Nexplane agent chooses the rest
- →Full config for inference and serving
- →Nexplane handles infra, recovery, and endpoints

- →Full config + agent pre-flight review
- →Cost, time-to-ready, and capacity estimates
- →Accept or override recommendations

- Model source and deployment name
- Serving preferences, replicas, and latency targets
- Deadline and region constraints
- Accelerator selection and compute provisioning
- Inference server setup, endpoints, and retries
- Health monitoring and failure recovery
- Logs, metrics, and cost tracking